
Group leader Rajeev Thakur
Develops high-performance inference to support fine-tuned versions of AuroraGPT for specialized purposes.
Group leader Rajeev Thakur
The goal of the AuroraGPT Inference Team is to build, maintain, and provide scalable inference services and APIs to enable the AuroraGPT community to access various state-of-the-art LLMs.
We have developed an inference service that uses the computational power of ALCF HPC systems (e.g., Polaris and Sophia). As shown in the figure, a RESTful service, hosted on a CELS virtual machine, enables authenticated users to interact easily with various LLMs running on Polaris and Sophia. Leveraging a Django Ninja asynchronous API, a Postgres database, and the Globus Compute service, this solution allows for the remote execution of a large number of parallel LLM computations on HPC nodes through an OpenAI-API-compatible interface. Currently, we are serving several state-of-the-art models, such as Meta’s Llama 3.1 70B-Instruct and Mixtral-8x22b-instruct-v0.1. These LLMs are being used for various scientific applications, such as the automated generation of comprehensive textual descriptions of genomic features from raw data records.
Through Globus Compute, the inference service dynamically acquires the necessary resources to run the targeted LLMs. It can acquire more resources elastically if needed, without any human intervention, and can run an arbitrary number of LLMs simultaneously provided enough resources are physically available on the target cluster. We have developed a comprehensive metrics dashboard that offers valuable insights, including total requests, user activity per model, average latency, and weekly usage trends. This dashboard allows us to efficiently monitor performance and usage patterns, thereby helping identify high-traffic periods and ensuring optimal service delivery.
Our current efforts are focused on benchmarking the inference service, improving its performance and scalability, and serving large models running across multiple nodes.
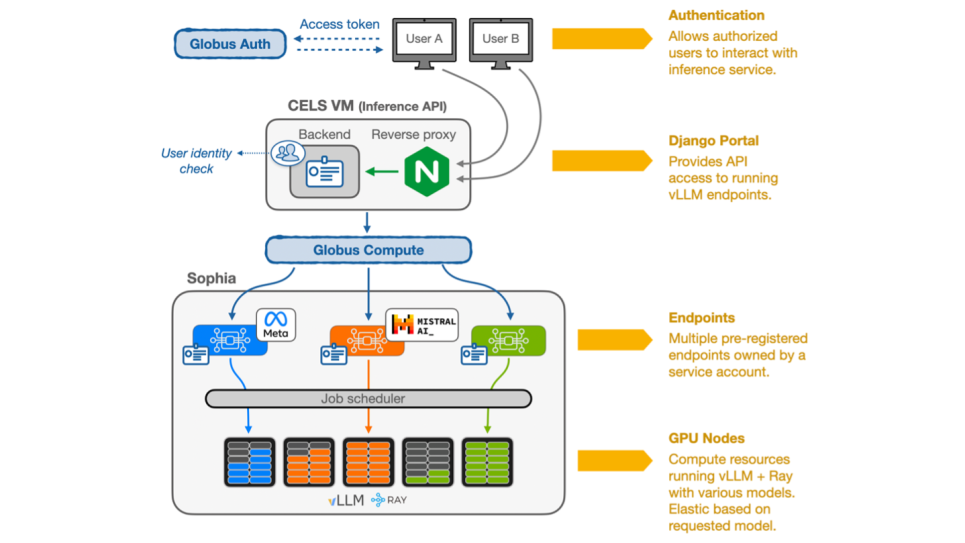
Architecture of the Globus-Compute-based inference service that we have developed for serving LLMs on the Sophia GPU cluster at ALCF. Authenticated and authorized users can make requests to run supported LLMs; requests are routed to compute resources on Sophia nodes.